Si tu empresa no es visible para un LLM, simplemente no existe.
Estamos viviendo el paso del clic a la inferencia. Ya no buscamos en listas; preguntamos a asistentes.
Y aquí está la pregunta incómoda para los directivos de marketing y tecnología:
¿Qué dice ChatGPT, Claude o Perplexity cuando un usuario pregunta por tu solución?
Si la respuesta es «No tengo información específica» o, peor aún, recomienda a tu competencia, tienes un problema de AI Visibility.
He dedicado los últimos meses a perfeccionar una metodología propia para resolver esto.
La he llamado AI Visibility y no es SEO convencional; es ingeniería de autoridad para la era de los agentes autónomos.
¿Qué estamos optimizando realmente?
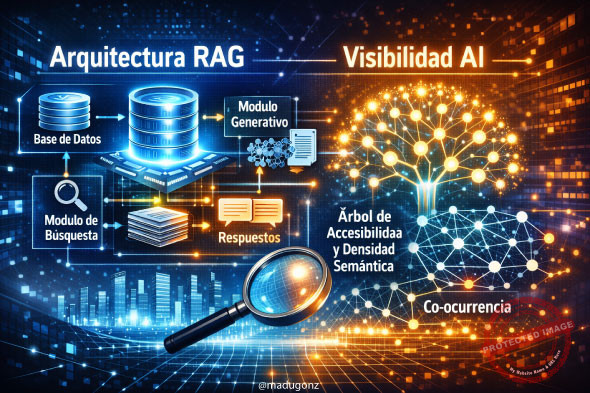
Arquitectura RAG Retrieval-Augmented Generation
No basta con estar indexado. Optimizamos tus activos digitales para que los modelos recuperen tu información con un Precision@K superior.
El Árbol de Accesibilidad El «Tercer Ojo»
Los agentes de IA no miran tu diseño; leen tu estructura técnica pura. Si tu árbol de accesibilidad es deficiente, eres invisible para el robot.
Densidad Semántica y Co-ocurrencia
Forzamos la asociación neuronal entre tu marca y tu categoría dentro del espacio vectorial de los grandes modelos de lenguaje LLMs.
Arquitectura RAG Retrieval-Augmented Generation: Precision@K superior
La RAG es una técnica que combina la recuperación de información retrieval con la generación de texto generation.
Un modelo RAG, ante una pregunta, no responde solo con su conocimiento interno estático, sino que primero busca fragmentos relevantes en una base de datos externa como documentos web, FAQs, manuales y luego genera una respuesta basada en esos fragmentos.
El problema que resuelve
Que tu contenido esté «indexado» por ejemplo, en Google no garantiza que un LLM tipo GPT-4, Claude o Gemini lo recupere durante su paso de búsqueda.
La mayoría de los LLMs comerciales usan RAG para conectar con fuentes actualizadas.
Si tu información no está optimizada para esta recuperación, el modelo la ignorará, aunque exista.
Precision@K superior
Es una métrica crítica. Mide, entre los K fragmentos recuperados ej. los 5 primeros, cuántos son realmente relevantes para la consulta.
Una Precision@5 del 100% significa que los 5 fragmentos que el RAG extrajo sirven para responder.
Una marca con alta AI Visibility consigue que sus fragmentos ocupen los primeros puestos (high precision) frente a los de la competencia.
Optimización práctica
Estructurar la información en chunks fragmentos lógicos, autocontenidos y con metadatos ricos.
Usar títulos y subtítulos que respondan a preguntas explícitas «Cómo instalar X», «Precio de Y en 2026».
Incluir variaciones léxicas y sinónimos densidad semántica para que el embedding coincida con múltiples formas de preguntar.
El Árbol de Accesibilidad El «Tercer Ojo» de la IA
El árbol de accesibilidad Accessibility Tree es una estructura técnica que los navegadores y sistemas operativos generan a partir del DOM Document Object Model de una página web.
Está pensado originalmente para lectores de pantalla personas con discapacidad visual, pero los agentes de IA asistentes virtuales, web scrapers semánticos, crawlers de LLMs lo utilizan como su interfaz prioritaria para entender la jerarquía, roles y relaciones de los elementos.
Por qué es el «Tercer Ojo»
Mientras los humanos ven diseño visual colores, tipografías, imágenes, los agentes de IA no «miran». Leen el árbol de accesibilidad: heading level 1, button, link, article, list item.
Si ese árbol está mal construido ej. encabezados saltados, botones sin etiqueta, imágenes sin alt text, la IA percibe un caos o vacío.
El resultado es invisibilidad técnica: el agente no sabe qué acción tomar ni qué contenido extraer.
Deficiencias comunes que causan invisibilidad:
Uso de div con clases CSS como «titulo» en lugar de <h1>.
Menús de navegación sin roles ARIA role=»navigation».
Contenido dinámico JavaScript que no actualiza el árbol de accesibilidad.
Imágenes relevantes sin alt descriptivo solo se indexa como «imagen».
Optimización
Construir HTML semántico no solo visualmente correcto.
Validar con herramientas como Lighthouse, axe o WAVE; no para cumplir normativa WCAG sino para garantizar legibilidad por IA.
Incluir aria-label y aria-describedby en elementos interactivos críticos.
Densidad Semántica y Co-ocurrencia: Forzar la asociación neuronal
Los LLMs representan palabras y conceptos como vectores en un espacio de alta dimensión embedding.
La densidad semántica es la concentración de términos relacionados con un tema central dentro de un fragmento de texto.
La co-ocurrencia es la frecuencia con que dos términos ej. «tu marca» y «tu categoría de producto» aparecen cerca en el mismo contexto durante el entrenamiento o en los textos que consume el modelo.
El objetivo
Que el modelo asocie tu marca con la categoría como un par inseparable en su espacio vectorial.
Por ejemplo: si vendes análisis de datos, quieres que «DataWise» y «business intelligence» tengan una distancia euclidiana muy pequeña y un alto coseno de similitud.
Por qué forzarlo activamente
Si no trabajas esta asociación, el LLM podría vincular tu categoría con marcas competidoras que sí aparecen densamente en sus datos de entrenamiento o en los documentos RAG.
La co-ocurrencia pasiva favorece a los gigantes; la activa la construyes tú.
Tácticas de implementación
Crear contenido donde «Marca X» y «Categoría Y» aparezcan juntos en patrones naturales no spam: listas, comparativas, estudios de caso.
Usar variantes contextuales: «Como líder en [categoría], [marca] resuelve…», «Herramientas de [categoría] como [marca]».
Aprovechar el prompt engineering público: publicar preguntas/respuestas donde el modelo idealmente debería evocar tu marca ante la categoría.
Incluir relaciones semánticas también en metadatos, schemas JSON-LD y en el texto alternativo de imágenes.
Riesgo a evitar
Forzar co-ocurrencia de forma no natural keyword stuffing puede ser penalizado por sistemas de calidad de los LLMs o por los propios filtros RAG.
La clave es la relevancia contextual.
Resumen integrador para una estrategia de AI Visibility
| Concepto | Qué resuelve | Métrica clave | Error típico |
| RAG + Precision@K | Que el modelo recupere tu contenido en el momento de la consulta | Precision@K ej. 4/5 | Tener información pero en fragmentos mal estructurados |
| Árbol de accesibilidad | Que el agente de IA entienda la jerarquía y funciones de tu página | Puntuación Lighthouse / ausencia de errores ARIA | Diseñar solo para humanos, ignorando el DOM semántico |
| Densidad semántica y co-ocurrencia | Que el LLM asocie tu marca directamente con tu categoría | Proximidad de embeddings cosine similarity | Asociación débil o dependencia de menciones genéricas |
En conjunto, estos tres pilares hacen que una marca no solo exista en la web, sino que sea visible, comprensible y recuperable por los modelos de IA que hoy dominan la búsqueda, la respuesta automatizada y la interacción con agentes autónomos.
El beneficio de negocio es directo: No se trata solo de tecnología. Se trata de Revenue.
Ser la fuente de verdad recomendada por una IA reduce la fricción en el embudo de ventas y te posiciona como el líder indiscutible de tu sector ante una audiencia que ya no usa Google de la misma manera.
He sintetizado toda esta estrategia de Agent-Readiness en mi nueva página especializada.
Si quieres entender cómo evaluamos los «Tres Ojos de la IA» y cómo preparar tu infraestructura para el tráfico del futuro, echa un vistazo aquí:
Así «piensa» la IA en tu marca: El poder de la densidad semántica
La IA no es el futuro, es el rastreador que está leyendo tu web ahora mismo. ¿Estás preparado?











